
Google Research just dropped ReasoningBank, and honestly, it’s one of the more practical agent memory ideas I’ve seen in a while.
The problem with most agents today is they’re forgetful in the worst way. They’ll nail a complex web navigation task, then turn around and make the exact same strategic error on the next one because they never bothered to remember what went wrong. Existing memory approaches either log every single action (trajectory memory, like Synapse) or only summarize successful workflows (Agent Workflow Memory). Both miss the point.
The core insight
ReasoningBank flips the script by distilling high-level reasoning patterns from both wins and losses. Instead of storing “click button X at coordinate Y,” it stores something like “always verify the current page identifier first to avoid infinite scroll traps before attempting to load more results.” That’s a transferable strategic insight, not a brittle procedural log.
Each memory item has three fields: a title (quick identifier), a description (summary), and the actual content (distilled reasoning steps or decision rationales). The system runs a continuous loop: retrieve relevant memories, interact with the environment, self-assess the trajectory using an LLM-as-a-judge, then extract new insights. The self-judgment doesn’t need to be perfect — the authors found ReasoningBank is surprisingly robust against judgment noise, which is reassuring because LLM-as-a-judge approaches can be flaky.
Why failures matter
This is where I think ReasoningBank really shines. Most memory systems only care about successful runs, but failures are where the real learning happens. By actively analyzing failed trajectories, ReasoningBank extracts counterfactual signals and pitfalls, turning mistakes into preventative lessons. That’s how you get an agent that doesn’t just repeat what worked, but actively avoids what didn’t.

Memory content comparison: existing strategies vs. ReasoningBank.
The workflow
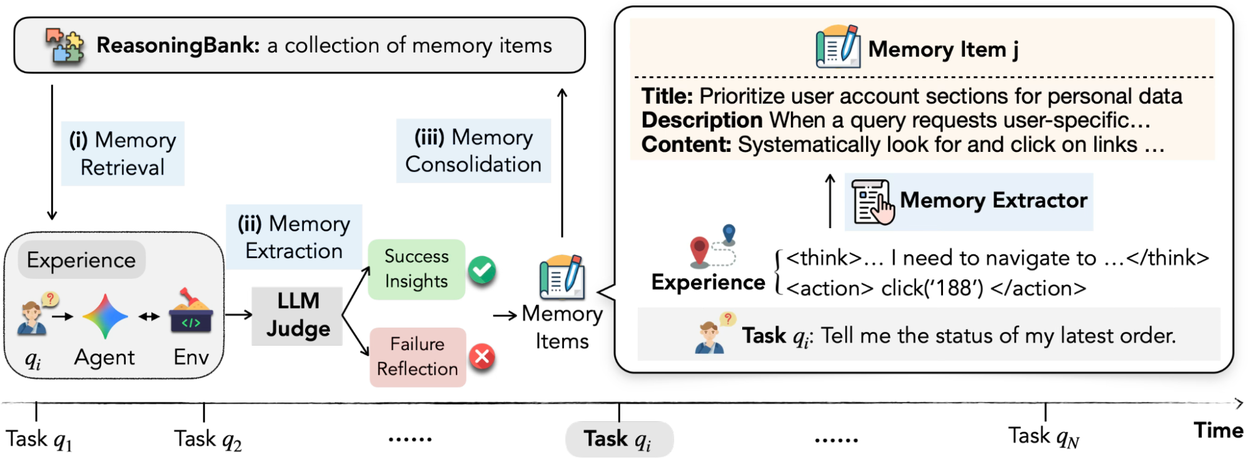
Workflow of ReasoningBank integrated with an agent during test time.
The process is straightforward: before acting, the agent pulls relevant memories from the bank. After the task, it evaluates the trajectory, extracts insights, and appends them. The authors acknowledge the consolidation strategy is basic (just appending), and they leave more sophisticated merging for future work. That’s fine — the framework is already useful as-is.
Does it actually work?
On web browsing and software engineering benchmarks, ReasoningBank improved both success rates and efficiency (fewer steps per task) compared to baselines. That’s higher than I expected for a first cut. The efficiency gains are particularly interesting — better reasoning patterns mean less flailing around.
One thing I appreciate is the paper doesn’t oversell. They’re upfront about the simple consolidation strategy and note that the self-judgment doesn’t need to be perfect. It’s a refreshing change from the usual “our method solves everything” tone.
My take
ReasoningBank is a solid step toward agents that actually learn from experience rather than just accumulating action logs. The focus on transferable reasoning patterns over procedural steps is the right direction. I’d like to see more sophisticated memory consolidation in future versions — right now it’s just appending, which means the bank could grow unwieldy. But for a first release, this is promising. The code is on GitHub if you want to poke around.
If you’re building persistent agents that need to operate over long periods, this is worth a look. Just don’t expect it to magically fix all your agent’s problems — it’s a memory framework, not a silver bullet.
Comments (0)
Login Log in to comment.
Be the first to comment!